

Lambda, Kappa, and Delta architectures
The Greek alphabet of data.

Kappa, Lambda, and Delta are three data architectures commonly used in big data processing. Choosing the correct architecture for your data needs is the first crucial step when setting up the entire project. It defines how the pipelines - and the entire data flow - will be built.
For a quick overview, let’s put them in single-sentence definitions:
Kappa Architecture: A single pipeline, streaming-based data processing architecture with no separation between real-time and batch processing.
Lambda Architecture: A hybrid architecture that processes data in both batch and real-time pipelines and combines the results for serving data.
Delta Architecture: A three-layered architecture that addresses the limitations of both Kappa and Lambda architectures, and offers the ability to update and delete data in real time.
Kappa Architecture
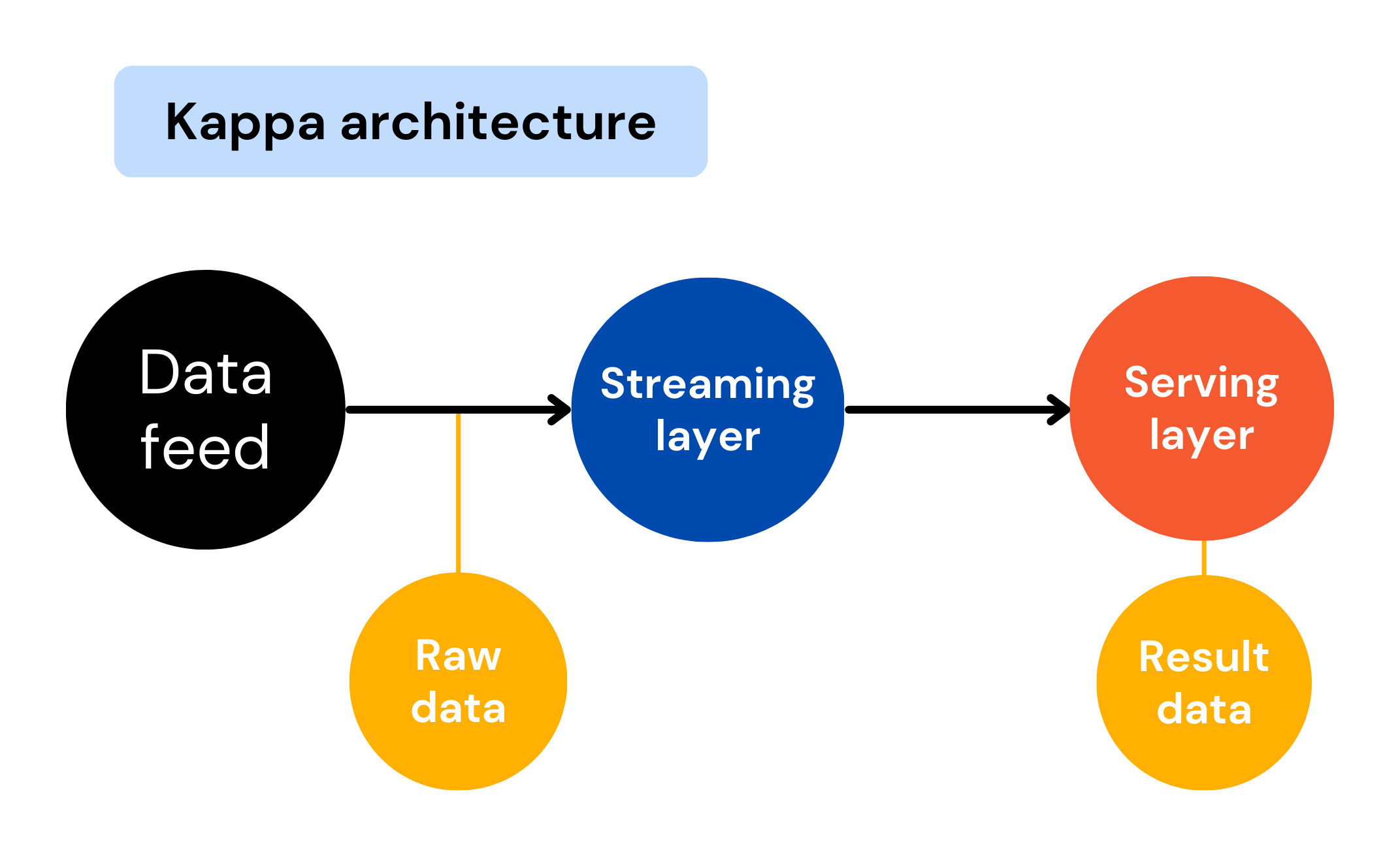
Data is processed in a single pipeline
Uses a streaming framework —> everything is a stream
Storage is typically in a distributed system (example: HDFS)
No separation between real-time and batch processing
Has a simpler architecture compared to Lambda and Delta
Lambda Architecture
Data is processed in two separate pipelines: batch and real-time
Uses both batch processing frameworks (e.g., Hadoop) and real-time streaming frameworks (e.g., Apache Kafka)
Storage is typically in a distributed system like HDFS or Apache Cassandra
Results from both pipelines are combined for serving data
Has a more complex architecture compared to Kappa and Delta
The lambda architecture, despite its complexity, has been one of the most used out of all three in recent years. Even though it’s widely used, lambda architecture isn’t all rainbows and sunshine. It’s considered to be the “middleman” between a traditional data store and DWH’s.
Delta Architecture
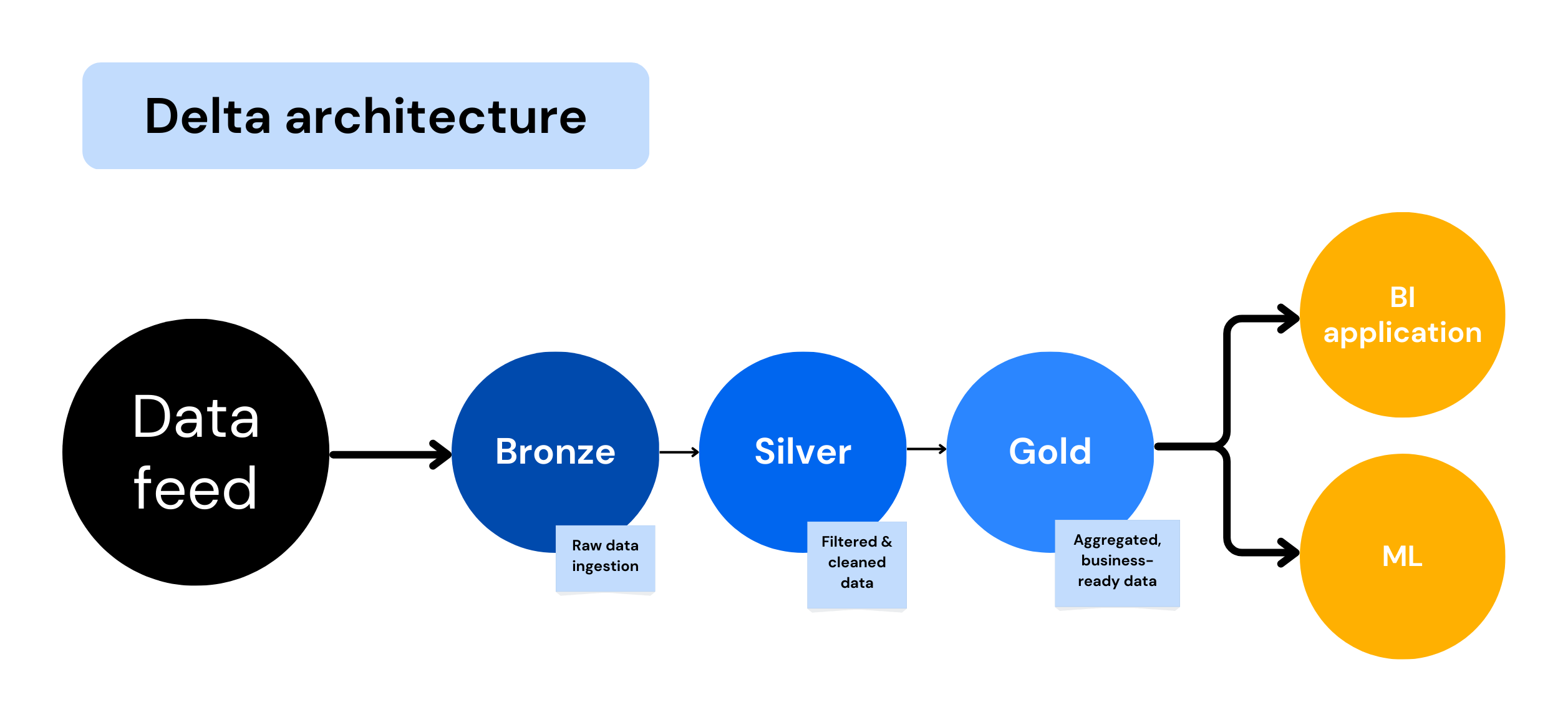
Data is processed in three layers: batch, speed, and serving
Uses a combination of batch-processing frameworks, stream-processing engines, and real-time databases
Storage is typically in a data lake or a cloud-based storage system
Offers the ability to update and delete data in real-time, which is not possible in the other two architectures
Designed to address the limitations of both Kappa and Lambda architectures
And then, a few years ago, there was a new competitor on the market. The delta architecture started to gain popularity, because - as Databricks describe it - Simplicity Trumps Complexity for Data Pipelines. To simplify the delta architecture - you take both streaming and batch data, and squish them both into a Delta Lake format. Combining them is the first (usually the most impossible) step in a data engineering job. After you’ve got the data in a bronze table (raw ingestion), the data goes to a Silver table where it’s cleaned and filtered. The data in Gold tables should be business ready, to be used in either analytics or AI & reporting.
Similarities
Even though there are differences between all three, they are all big-data processing architectures, meant to streamline a large volume of data. All three architectures are designed to handle large amounts of data in a scalable and fault-tolerant way. They all use distributed storage systems. They all employ a combination of batch and real-time processing.
In conclusion, the decision on which architecture to use relies upon both the manpower and complexity you’re able to keep up, as well as the data types and the corresponding architecture that already exists.
Each architecture has its own strengths and weaknesses, and choosing the right one depends on your specific use case and business requirements. The Kappa Architecture offers simplicity and real-time processing, while the Lambda Architecture offers a hybrid approach for both batch and real-time processing. The Delta Architecture builds on both Kappa and Lambda, and offers the added benefit of real-time updates and deletions. By understanding the differences and similarities between these architectures, you can make an informed decision and choose the one that best fits your needs.